데이터 및 C언어/Python 공부 내용
[Python] Python의 scipy라이브러리 중 Numpy[수치 계산 라이브러리]
- -
반응형

[Python] Python의 scipy라이브러리 중 Numpy[수치 계산 라이브러리]
데이터 분석을 함에 있어서 최근 가장 많이 활용되는 것이 SQL과 파이썬의 라이브러리들입니다.
라이브러리에는 [Pandas, Numpy, Scipy, Matplotlib, Seaborn, Tensorflow, Keras] 등 다양한 분석을 위한 라이브러리들이 존재합니다.
이번 글에서는 라이브러리들 중 Numpy에 대해서 대략적으로 알아보는 시간을 가져보겠습니다.
Numpy는 "Numerical Python"의 줄임말로, C언어로 구성된 수많은 파이썬 라이브러리들 중
파이썬에서 고성능의 수치계산을 쉽게 할 수 있도록 도와주는 강력한 라이브러리입니다.
벡터 및 행렬 연산에 있어서 매우 편리한 기능을 제공합니다.
∇ Numpy의 장점.[공식사이트에 적혀있는 장점]
- # POWERFUL N-DIMENSIONAL ARRAY [다차원 배열 ]
- : NumPy에서 배열 및 벡터를 표현하는 핵심 구조인 ndarray를 사용하여 빠르고
- 메모리를 효율적으로 사용할 수 있게 합니다.
- # NUMERICAL COMPUTING TOOLS [풍부한 함수 ]
- :반복문을 작성할 필요 없이 전체 데이터 배열에 대해 빠른 연산을 제공하는 다양한 표준 수학 함수를 제공한다.
- # PERFORMANT [ 빠른 연산 속도 ]
- :잘 최적화하여 컴파일된 C/C++ 코드를 사용하여 빠른 연산을 가능하게 합니다.
∇ Numpy 프로그래밍 기초 정복.


- 행렬 및 벡터연산을 위해선 다차원array를 사용해야합니다.
- NumPy에선 이러한 다차원 array형태인 핵심적인 객체를 ndarray[넘파이의 기본 자료형]라고 부르며
파이썬의 기본 내장 객체인 array와는 다르게 아래와 같은 속성들을 가지고 있습니다.
기존 배열과 외관은 동일하지만, 내부 소스코드 구조가 달라 기존 배열 대비 속도가 빠릅니다.

∇ 기본 배열 생성.[np.array ]
: NumPy의 배열 생성은 기본적으로 np.array() 함수를 통해 파이썬 list를 인자로 받아 생성할 수 있습니다.


√ 배열을 생성하는 여러가지 방법.
≫ 리스트를 배열로 변환.
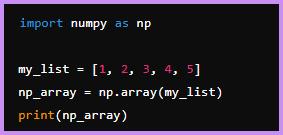
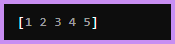
≫ 특정 값으로 채워진 배열 생성.
- np.zeros(n) : n개의 요소가 0인 배열을 생성
- np.ones(n) : n개의 요소가 1인 배열을 생성.


- np.empty(n) : n개의 요소가 무작위인 배열을 생성, 메모리 상태에 따라 다랄짐
빠른 속도를 이용해 효율적인 메모리 활용 위해 사용

-np.linspace(x,y,z)
: x번째 인자 ~y번째 인자까지 범위 내에서 z번째 인자 갯수만큼 선형 간격(일정간격)을
가진 숫자들을 배열로 반환.

≫ 연속된 숫자로 배열 생성.


≫ 배열의 요소 추가, 제거 및 정렬.
-np.sort()
: 요소를 정렬하는 함수로, 오름차순으로 빠르게 정렬.
+ 원본은 변경하는 것이 아닌, 정렬된 배열을 복제하여 반환(원본 유지)

- np.concatenate()
: 배열을 정렬하는 함수.

∇ NumPy 확인 메서드.
- 넘파이 객체는 아래와 같은 명령어로 차원 타입 등을 확인 가능.
| 객체.dtype | 객체의 타입(list, ndarray, tuple) |
| type(객체) | 객체의 데이터 타입(int32, float64) |
| 객체.ndim | 차원확인 |
| 객체.shape | 구조확인(shape)-객체의 행과 열에 대한 정보 튜플로 반환. |
∇ Numpy의 연산.
∇ 기본 연산.

- numpy에서 더하기,뺴기와 곱셉은 +와 *를 사용하고,
나누기는 @연산자 혹은 dot()함수를 사용합니다.

∇ 함수 연산.
- sum(), min(), max()와 같은 함수를 통해 연산 가능.

728x90
반응형
'데이터 및 C언어 > Python 공부 내용' 카테고리의 다른 글
| [Python] 파이썬 라이브러리 넘파이 공부하기(1)-배열생성 (0) | 2024.07.06 |
|---|---|
| [Python] Python 라이브러리 Numpy에서의 행렬 다루기. (0) | 2024.07.04 |
| [Python] 파이썬 *args(가변위치인자) & **kwargs(가변키워드인자) (1) | 2024.07.03 |
| [Python] 파이썬 텍스트 파일 다루기. (0) | 2024.07.02 |
| [Python] Python 공부하기 : 얕은 복사[shallow copy] vs 깊은 복사[deep copy] (0) | 2024.07.01 |
Contents
소중한 공감 감사합니다