데이터 및 C언어/SQL 공부
[SQL] SQL 공부 : View 및 Procedure.
- -
반응형

[SQL] SQL 공부 : View 및 Procedure.
1. View (뷰)
: view는 하나 이상의 테이블을 참조하는 가상 테이블입니다.
실제 데이터를 저장하지 않고, 사용자가 쿼리의 결과를 마치 테이블처럼 사용할 수 있게 해줍니다.
뷰를 사용하면 복잡한 쿼리를 단순화하고, 데이터 보안을 강화할 수 있습니다.
- 기본 테이블은 디스크에 공간이 할당되어 데이터를 저장함.
- 뷰는 데이터 딕셔너리(Data Dictionary) 테이블에 뷰에 대한 정의(SQL문)만 저장되어,
디스크 저장 공간 할당이 이루어지지 않습니다.
- 가상의 테이블을 생성.
- 실제 테이블처럼 행과 열을 가지고 있지만, 데이터를 직접 저장하고 있지는 않음
- 다른 테이블이나 다른 뷰에 저장되어 있는 데이터를 보여주는 역할만 수행.
- 전체 데이터 중에서 일부에만 접근 가능하도록 합니다.
- 뷰에 대한 수정 결과는 '뷰를 정의한 기본테이블'에 적용됩니다.
- 뷰를 정의한 기본 테이블에서 정의된 무결성 제약조건은 그대로 유지됩니다.
∇ 뷰를 만드는 이유.
1. 데이터 추상화.
- 복잡한 쿼리를 단순화하여서, 사용자가 필요한 데이터만 쉽게 볼 수 있게 합니다.
- 데이터베이스 구조의 변경이 있어도 최종 사용자에게 영향을 주지 않습니다.
2. 보안 강화.
- 민감한 데이터를 숨기고 필요한 정보만 제공할 수 있습니다.
- 사용자별로 다른 뷰를 제공하여, 접근 권한을 세밀하게 제어 가능합니다.
3. 데이터 일관성 유지.
- 동일한 데이터에 대해 항상 같은 방식으로 접근할 수 있게 합니다.
- 비즈니스 로직을 뷰에 포함시켜 일관된 데이터 해석을 보장합니다.
4. 쿼리 성능 향상.
- 자주 사용되는 복잡한 쿼리를 뷰로 만들어 재사용함으로써 쿼리 실행 시간을 단축할 수 있습니다.
5. 레거시 시스템 지원.
- DB 구조가 변경되어도 기존 애플리케이션이 계속 작동 가능하도록 뷰를 통해
이전 구조를 유지할 수 있습니다.
∇ 뷰의 장*단점.
# 장점.
- 복잡한 쿼리 단순화/ 쿼리의 재사용성 증대
- 논리적 독립성을 제공함.
- 데이터의 접근 제어(DB 보안)
- 필요한 필드만 보여줄 수 있음.
- 일관된 접근 방식을 제공.
- 사용자의 데이터 관리 단순화.
- 여러 사용자의 다양한 데이터 요구 지원 가능.
# 단점.
- 한번 정의된 View의 정의 변경 불가.
- 삽입, 삭제, 갱신 연산에 제한이 있습니다.
- 자신만의 인덱스를 가질 수 없습니다.
- 기본 테이블 구조가 변경되면, View도 수정해야 할 수 도있습니다.
∇ 뷰의 생성 * 대체*수정 * 삭제.
1 . 뷰 생성하기.
# 뷰는 원본 테이블과 같은 이름을 가질 수 없습니다.
: create view 뷰이름 as 쿼리(sql)

ex)



2. 뷰 대체하기.
: CREATE OR REPLACE VIEW문을 사용합니다.

3. 뷰 수정하기
: ALTER VIEW 뷰이름 AS 쿼리.

4. 뷰 삭제하기.
: DROP VIEW 뷰이름;

#주의사항#
- 뷰 생성 시 권한 : 뷰를 생성하려면 권한이 필요합니다.
- 기본 테이블 의존성 : 뷰의 기본테이블이 변경되면 뷰도 영향을 받을 수 있습니다.
- 업데이트 가능한 뷰: 일부 뷰는 특정 조건 하에서 업데이트가 가능합니다.
하지만 복잡한 뷰는 업데이트가 제한될 수 있습니다.
- 성능 고려: 복잡한 뷰는 쿼리 성능에 영향을 줄 수 있으므로 주의해서 사용해야 합니다.
- 보안: 뷰를 사용하여 민감한 데이터에 대한 접근을 제한할 수 있지만, 적절한 권한 설정이 필요합니다.
∇ 뷰의 종류.
# 단순 뷰.
: 하나의 기본 테이블 위에 정의된 뷰
#복합 뷰.
: 두개 이사의 기본 테이블로부터 파생된 뷰.
2. Procedure(프로시저) - 매개변수.
: Procedure는 MySQL에서 일련의 SQL 명령어를 하나의 함수처럼 실행할 수 있게 해주는 저장 프로그램.
[ 프로시저는 일련의 쿼리를 하나의 함수처럼 실행하기 위한 쿼리의 집합.]
- 복잡한 처리를 캡슐화하고 재사용성을 높이는 데 매우 중요합니다.
[매개 변수를 받을 수 있고 반복적으로 사용할 수 있는 블럭입니다.]
# 프로시저의 기본 구조.
: 프로시저를 생성하려면 'CREATE PROCEDURE' 명령어를 사용합니다.

DELIMITER $$
- 프로시저 구문과는 관련이 없는 명령어로, 표준 구분 기호인 세미콜론(;)을 다른 기로 ($$)로 변경합니다.
- Mysql도구가 매번 각 문장을 실행하는 것보다 서버에 프로시저를 통과시키는 것이 중요하기 때문입니다.
- CREATE PROCEDURE : 프로시저 생성을 시작합니다
- BEGIN과 END : 프로시저의 본문을 감싸는 블록,
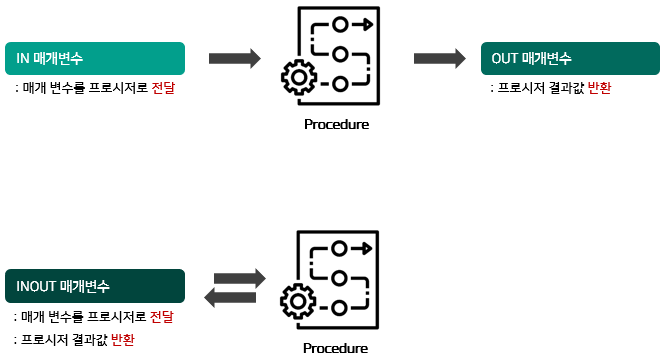
∇매개변수 유형.
- IN : 입력 매개변수, 호출할 때 값을 전달 받습니다.
- OUT : 출력 매개변수, 프로시저가 실행된 후 값을 반환합니다.
- DECLARE : 변수를 선언하는 경우 사용합니다.
- INOUT : 입력 및 출력 매개변수, 호출할 때 값을 전달받고, 실행된 후 값을 반환합니다.
생성예제.


- 프로시저 생성 시 중요한 부분은
프로시저명() 안에 있는 파라미터 선언부분,!
BEGIN ~ END 사이에 수행할 쿼리 부분!
- 파라미터는 프로시저 호출 시 특정 값을 넣어 호출할 경우,
그 값을 받을 파라미터의 이름과 데이터타입을 설정하는 것이고
- MySQL에서 프로시저(Procedure)를 사용해 주면,
여러 쿼리를 프로시저 하나로 실행시킬 수 있는데
- 함수(Function)와 비교해 보자면
함수는 쿼리를 수행한 후 값을 가져오는 것이 중점이지만,
프로시저는 여러 쿼리들을 한번엔 수행하는 것이 중점입니다.
728x90
반응형
'데이터 및 C언어 > SQL 공부' 카테고리의 다른 글
| [SQL] SQL 코딩 테스트 및 쿼리 연습. (0) | 2024.07.08 |
|---|---|
| [SQL] 데이터 마트와 데이터웨어하우스란 무엇인가? (0) | 2024.07.01 |
| [SQL] SQL 공부하기 : 함수 (1) | 2024.06.30 |
| [SQL] SQL 연산자 { 비교, 논리, 특수, 산술, 집합 } (1) | 2024.06.30 |
| [SQL] SQL 공부 : 서브쿼리. (0) | 2024.06.29 |
Contents
소중한 공감 감사합니다